nltk.download(‘punkt‘)报错 |
您所在的位置:网站首页 › python 3713 download › nltk.download(‘punkt‘)报错 |
nltk.download(‘punkt‘)报错
|
问题描述
在跑代码时,用到nltk库,但是出现如下问题: import nltk nltk.download('punkt') For more information see: https://www.nltk.org/data.html Attempted to load ?[93mtokenizers/punkt/english.pickle?[0m Searched in: - 'C:\\Users\\hp/nltk_data' - 'D:\\anacoda\\python3.6.5\\nltk_data' - 'D:\\anacoda\\python3.6.5\\share\\nltk_data' - 'D:\\anacoda\\python3.6.5\\lib\\nltk_data' - 'C:\\Users\\hp\\AppData\\Roaming\\nltk_data' - 'C:\\nltk_data' - 'D:\\nltk_data' - 'E:\\nltk_data' - ''  解决办法
解决办法
在使用nltk这个工具包时,需要的数据通常是不能通过nltk.download('xxx')下载下来的,我们可以从官网http://www.nltk.org/nltk_data/上下载需要的数据,比如punkt、stopwords等等。打开网站 http://www.nltk.org/nltk_data/ 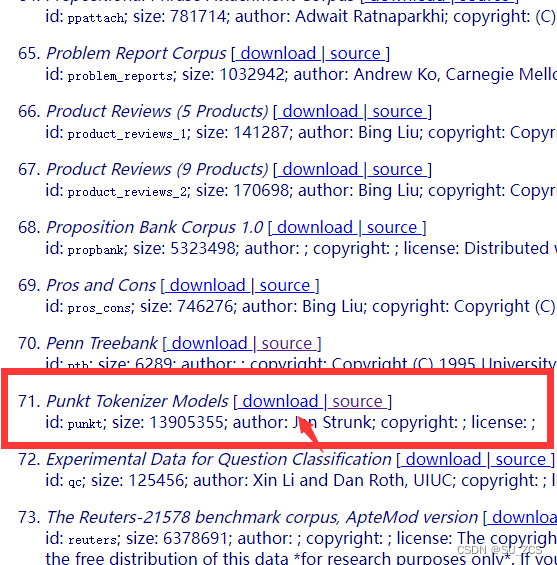
选择download下载 
在 C:\Users\xxx\AppData\Roaming 路径下创建文件夹 nltk_data,在nltk_data文件夹中再创建文件夹 tokenizers,punkt.zip 解压到C:\Users\xxx\AppData\Roaming\nltk_data\tokenizers 下,如下: 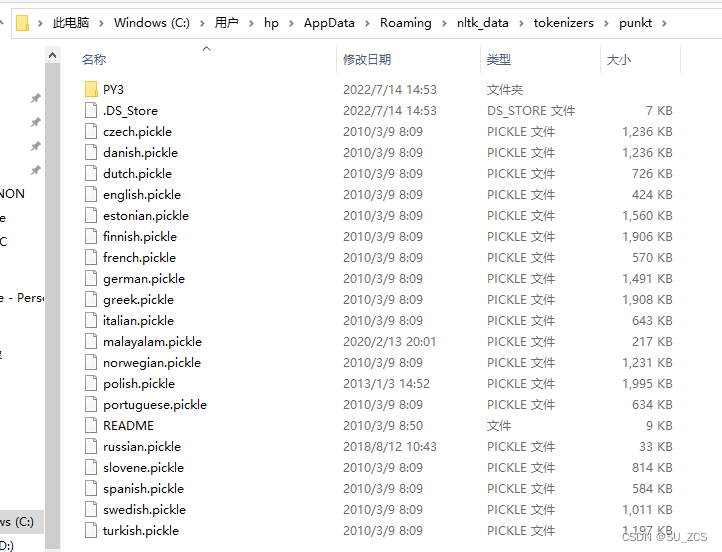
接下来进行测试 win+R cmd,输入python,再依次输入如下代码 import nltk text=nltk.word_tokenize("Barack Hussein Obama, born on August 4, 1961, is an American Democrat politician, the 44th president of the United States, and the first African-American president in the history of the United States.") print(text)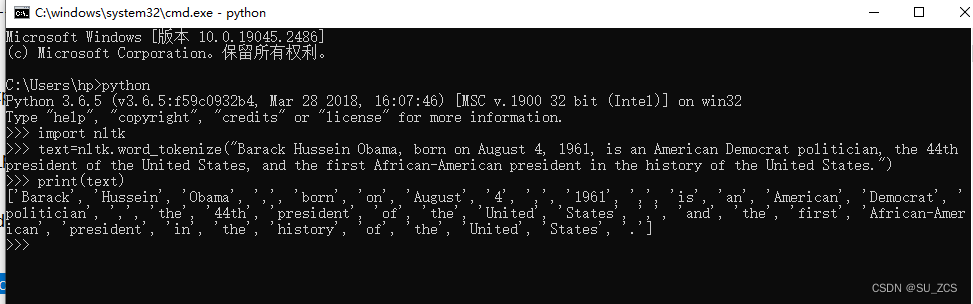
表示运行成功。 |
【本文地址】